画像認識のトレンドと今後に向けて
2021年1月25日
カテゴリー:レポート

1. はじめに
画像認識と聞いてまず思い浮かべるのは,デジタルカメラに搭載されている顔検出や,文字認識(OCR)の技術が一般的かと思います.しかしながら,一言に「画像認識」と言っても,顔や文字などの検出と認識,領域分割,人の姿勢推定などタスクは多岐に渡ります.
本稿では,様々なタスクに画像を用いる意義を皮切りに,深層学習を用いた画像認識,弊社での取り組みと今後の展望についてご紹介いたします.
2. なぜ画像か?
ヒトは五感を通して環境の情報を得ますが,五感のうち視覚が最も支配的であると言われています[1].
また,他の感覚器に比べて知覚できる距離が広く,両の眼により3次元的な知覚も可能です.ヒトが目で見て理解できるなら,目と同様の構造を持つピンホールカメラから得られる画像にも理解できるだけの情報は埋め込まれているはずです.この情報を如何にして上手く捉えるかが画像認識のキーとなります.
また,機械が理解した通りに入力画像に重ねて表示するだけでヒトは「機械がどう理解したか」を理解することができます.情報量の多さとヒトの理解のし易さが画像を用いるメリットと言えます.しかし,情報量が多いということはそれだけノイズも多くなります.いかに有用な特徴を捉えるかが画像認識の肝と言っても良いでしょう.
3. 深層学習を用いた画像認識
「人工知能概観」で触れられているように,画像特徴の抽出方法は2000年代ごろまで人間が手設計していましたが,現在では深層学習によって抽出すべき特徴までもデータから自動的に学習する方法が主流になっています.深層学習流行の発端は2012年の画像認識コンペティションImageNet Large Scale Visual Recognition Competition (ILSVRC)でAlexNet[2]として知られる深層学習の手法が既存手法に大差をつけて優勝したことでした.それ以降,画像認識のほとんどのタスクにおいて深層学習を用いた手法が多数提案されるようになり,今も世界中で活発に研究が進められています.
黎明期のネットワークは,1枚の画像に対して1つのクラスを当てる画像分類タスクに適用したものが主でした.当時は,入力画像サイズ固定(あるサイズにリサイズまたはトリミングする)かつ層を跨いだ連結のないネットワークが主流でしたが,層が深くなるほど情報が劣化し,学習が困難であるといった問題が露見しました.そこで,2015年にResNet (Residual Network)[3]という差分を覚えるネットワークが提案され (※引用文献はCVPR2016で発表されたもの),層が深くなっても有用な情報を失わずに学習できるようになりました.ResNetの台頭により画像認識の分野はまた一段上のステージへと進みました.
また,物体の検出と認識のタスクにおいても2014年のR-CNN (Regions with Convolutional Neural Networks)[4]を皮切りに多数の手法が提案されています.R-CNNは,物体領域候補を抽出し,各領域の部分画像を判別することで検出と認識を行います.R-CNNは物体領域候補を挙げる段階と物体認識を行う段階に分かれており,処理が重いことが難点でしたが,Faster R-CNN[5]やYOLO (You Only Look Once)[6],SSD (Single Shot Multibox Detector)[7]など1つのニューラルネットワークで検出も認識も行うことで高速化する手法も提案されています.
画像セグメンテーションの分野では,画像入力に対して画像出力が得られてかつ全ての層を畳み込み層とすることで入力画像サイズを可変にしたFCN (Fully Convolutional Network, FCN)[8] が提案されています.
その他にも画像生成やロボットの環境認識など様々なタスクに応用されており,まるで万能のようにも見える深層学習ですが,もちろん弱点が無いわけではありません.認識対象と規模にもよりますが,学習には通常数千数万のデータが必要です.また,層の数や各層のノード数(畳み込み層であればフィルタサイズ)といったネットワーク構造の最適化,については未だ発展途上の問題です.
学習データ量の問題については,異常検知や大規模災害の予知のような学習データが多量に集められない場合にどう解決するかが流行の兆しを見せています.一つの解として,架空のリアルな画像を生成することのできるGAN (Generative Adversarial Network)[9]やコンピュータグラフィックスを用いてリアルな画像を人工的に生成することで学習データを増やす方法が提案されており,個人的に今後の発展に注目しています.
4. 構造計画研究所での取り組み
構造計画研究所では,インフラ設備の維持管理業務の改善や製造業の生産管理効率化などに画像を用いる方法を提案しています.全てに深層学習を用いるわけではなく,課題に合わせた特徴抽出・機械学習手法を選択しています.特にインフラ設備の維持管理では,「異常」の検出が目的となることが多く,学習データを収集することが困難であるため,異常検知の知見と融合したり,既存の異常例を加工することで学習データを増やしたりといった工夫をしています.具体的な事例としては,建物や道路などのひび割れ検出(図3-1,「中低層RC造ビル向けひび割れ検知カメラシステム」参照),鋼管内部劣化診断などがあります.製造業の方では,塗装面の小さな打刻(または印刷)文字の認識(図3-2参照),図面からの要素抽出などに取り組んでいます.
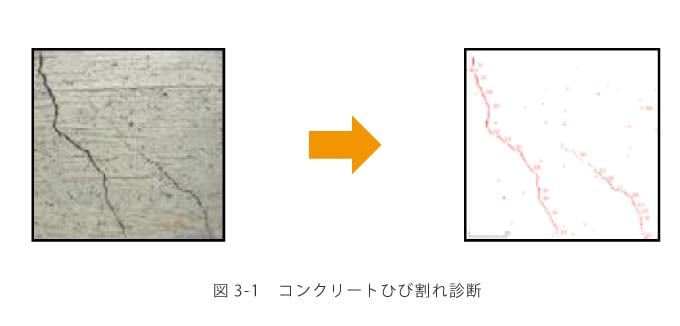
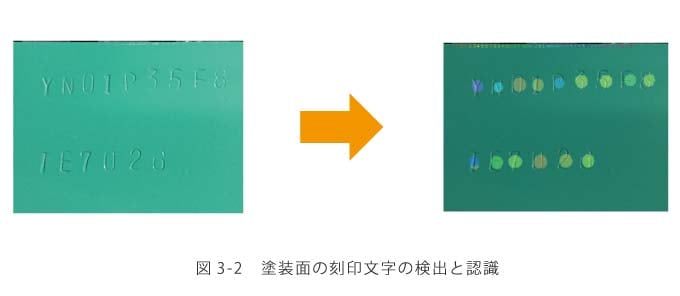
塗装面に打刻された文字は,照明条件によって見え方が大きく変化するため既存のOCRのツールでは検出も読み取りも困難でしたが,FCNを用いて検出と認識を1つのネットワークで行うことで,1000枚程度の学習データから97%以上の再現率と適合率を達成しました.
5. 今後の展望
今後は,まず学習データが多量に集められない場合の対策を盤石なものにしていきたいと考えています.また,現時点では前述のようなモノを対象とした画像認識に取り組んでいますが,各種業務を改善する上で欠かせないのが人間の行動の計測です.人体の姿勢を推定するソリューションは既に世の中にいくつもありますが,行動の意味付けや異常行動の検知,熟練技術のモデル化などまだまだ研究段階であり発展の余地は残されています.そういった人間行動認識の最新技術をキャッチしつつ,実業界に適用してゆくことで,より良い未来をつくることが今後のミッションと捉えています.
〔参考文献〕
[1] 岩村吉晃 他, “感覚生理学”,金芳堂, 1980.
[2] A. Krizhevsky, I. Sutskever, and G. E. Hinton. “Imagenet Classification with Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems (NIPS), 2012, pp.1097-1105.
[3] K He, X Zhang, S Ren, J Sun. “Deep Residual Learning for Image Recognition,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770-778.
[4] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 580-587.
[5] S Ren, K He, R Girshick, J Sun. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” Advances in Neural Information Processing Systems (NIPS), 2015, pp. 91-99.
[6] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi. “You Only Look Once: Unified, Real-Time Object Detection,” Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788.
[7] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg. “SSD: Single Shot MultiBox Detector,” European Conference on Computer Vision (ECCV), 2016, pp. 21-37.
[8] Jonathan Long, Evan Shelhamer, Trevor Darrell. “Fully Convolutional Networks for Semantic Segmentation,” Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 3431-3440
[9] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, “Generative Adversarial Nets,” Advances in Neural Information Processing Systems, 2014, pp. 2672-2680.
Contact
まずはお気軽にお問い合せフォームからお問い合わせください。