人工知能概観
2021年1月25日
カテゴリー:レポート

1. 人工知能研究の歴史(第1次,第2次AIブーム)
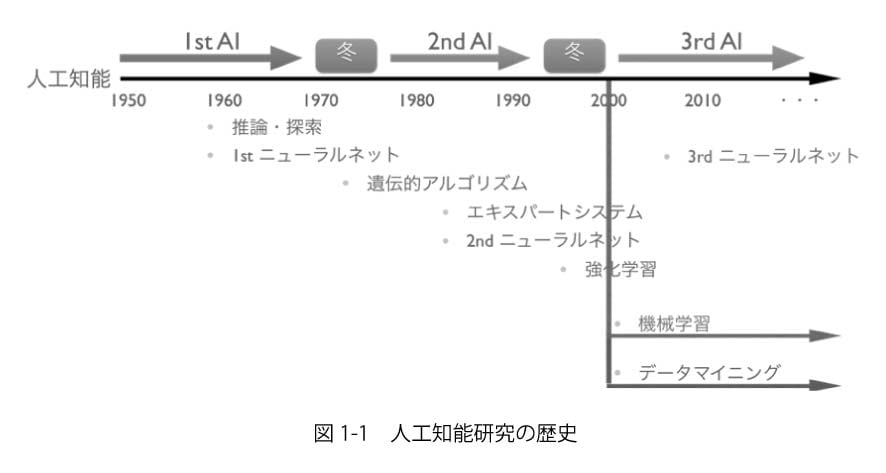
近年「人工知能(AI:Artificial Intelligence)」が非常に注目されていますが,これまでにも何度か「AIブーム」が存在しています.いつ頃,どのような技術が研究・開発されてきたかを押さえておくために,人工知能の研究の歴史について振り返ってみようと思います.
「人工知能」という用語が作られる前から人工知能と考えてよい理論・技術の研究はなされていますが,この用語自体は1956年のダートマス会議でジョン・マッカーシーによって命名されました.
以来,2度の「冬の時代」を経験しながら今の人工知能ブームに至ります(図 1-1).
第1次,第2次AIブームについては,詳細を割愛しますが,第1次では推論や探索が主な対象となっていました.また,第2次では遺伝的アルゴリズムや強化学習,ファジィ推論などが提案されています.
現在ブームの最中である第3次AIブームについては,次節以降で説明をしていきたいと思います.
2. 第3次AIブームの主役 ~ 機械学習 ~
2000年代から続く第3次AIブームを支える土台は「計算機の処理能力」,「データの豊富さ(IoT,ビッグデータ)」そして「機械学習」です.ここでは,第3次AIブームの主役である機械学習および深層学習について説明したいと思います.
「機械学習」については厳密な定義はありませんが,筆者がよく引用する表現は,「機械学習はデータからパターンを自動的に発見し,将来のデータの予測や意思決定に利用できる手法群である」というものです.
Machine learning is a set of methods that can automatically detect patterns in data, and then use the uncovered patterns to predict future data, or to perform other kinds of decision making under uncertainty.
(K. P. Murphy. Machine Learning: A Probabilistic Perspective. The MIT Press. 2012)
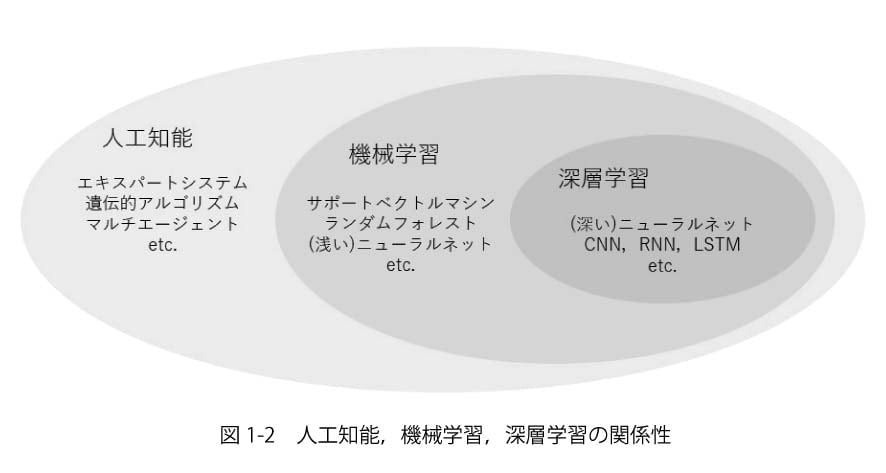
この表現の通り,機械学習と呼ぶ技術には様々な手法が含まれます.近年注目されている「深層学習」も機械学習の一つであり,図1-2のような関係性にあります.
機械学習は大きく分けて2つのグループに分けることができます.1つ目は入 – 出力関係を明らかにするための
「教師あり学習」であり,2つ目はデータに潜む情報・特徴を抽出するための「教師なし学習」です:
• 教師あり学習:入力と出力を関連付ける「関数」を学習
• 教師なし学習:データが潜在的にもつ「特徴」を抽出
株価予測や電力需要予測といった「回帰問題」や物体認識や音声認識といった「判別問題」に用いられる手法はいずれも「教師あり学習」に含まれます.一方,消費者セグメンテーションやレコメンドなどに用いられる手法は「教師なし学習」に含まれ,しばしば「データマイニング」と呼ぶ技術の一部とみなされます.
(教師あり)機械学習の「中身」を理解するために,簡単な例を使って説明したいと思います.
例えば,「身長から体重を予測する」という問題を考えた場合,機械学習の文脈では,以下のような言葉を使います.
身長と体重が線形,すなわち直線的な関係を持つと「仮定」すると,身長から体重を予測するモデルは,
体重=f(身長)=a×身長+b
と表すことができます.「学習する」とは,「身長と体重がセットになったデータ = 学習データ」を利用して,何らかの最適化手法によってモデルのパラメータ,上の例では傾きaと切片bを求めることを言います.
深層学習(特にディープニューラルネットワーク)への入り口として,上のモデルを,ニューラルネットワークを用いて表現してみます.
図1-3は「(線形)単層パーセプトロン」と呼ぶニューラルネットワークモデルで第1次AIブーム時に提案されたものです.このモデルでは非常に簡単な入 – 出力関係しか表現できませんが,「単層」となっている部分を(超)多層化し,様々な工夫をしたものが深層学習(ディープニューラルネットワーク)となります.深層学習の複雑さをイメージするために,モデルに含まれる(=学習対象となる)パラメータの数について紹介しておきます.
先ほどの例では学習対象のパラメータは傾きと切片の2つでした.
一方で,画像認識で用いられるCNNと呼ぶモデルでは,数年前の時点でパラメータ数が数千万,現在では数兆個と言われています.これほど複雑なモデルをうまく学習するためには,質の良いデータが大量に必要であることは想像に難くありません.
前述の通り,深層学習も他の機械学習と同様に「データからパターンを発見する」手法ですが,教師あり学習と教師なし学習(特徴抽出)の両方の側面を持ちます(図1-4).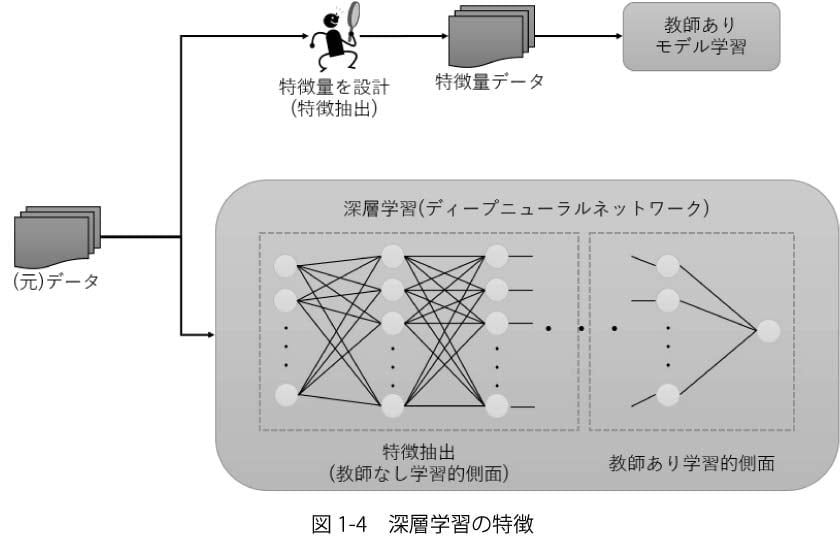
これまでの各種機械学習手法では,入力となるデータ(特徴量)は原則として人間が設計する必要がありました.例えば画像認識であれば,輝度勾配やカラーヒストグラムなどから得られる特徴的かつ有用と思われる情報を特徴量として利用します.また,音声認識であれば音声データをフーリエ変換し,それを基にした情報を特徴量として利用します.このような特徴量の設計(特徴抽出)は対象とするデータや目的によって異なることも少なくなく,手間のかかる手続きとなっていました.
一方で深層学習では,多層化されたニューラルネットワークを用いることで,自動的に適切な特徴量を抽出することが可能となりました.
3. 第3次AIブーム ~ 現在と今後 ~
前節で説明したように,現在のAIブームの主役である「深層学習」は大量のデータと高速な処理によって様々な分野において有効性が確認され,さらなる応用が期待されています.Googleのような企業は,そのデータ収集基盤とデータ処理基盤を活かし,非常に速いスピードで研究を進めています.そのような研究の中で「AIを作るAI(実際にはあるニューラルネットワークの構造を別のニューラルネットワークが自動的に決定する)」など先進的な技術も開発されており,一見すると「ターミネータ(あるいはマトリックス)の世界がすぐそこまで来ている」かのように感じられるかもしれません.
確かに,ここ数年のAI研究の規模と速度は目をみはるものがあり,数年先の世界観は正直なところ全く読めない状況です.しかしながら,最新のAI(深層学習)技術であっても,原則としては「特化型」,すなわち,特定の目的のために学習を行い,そのモデルは他の目的には使用できないものとなっています.また,学習には人の介在と大量のデータ,潤沢な計算環境が必須であることも忘れてはいけません.重要なことは,これらのことを踏まえた上で,課題解決にAIを取り入れるべきか,取り入れることは可能かを冷静に分析,判断していくことだと考えています.
Contact
まずはお気軽にお問い合せフォームからお問い合わせください。