インフラ維持管理の高度化 ~ テキストデータ活用編 ~
2021年1月25日
カテゴリー:レポート

1. インフラ維持管理における課題
現在の我々の生活は, 様々な「インフラ」により支えられています. 道路・鉄道などの交通インフラから,通信網・サーバ群などの通信インフラ,電力・ガスなどのエネルギーインフラなど多種多様です.当社では「インフラ維持管理の高度化」をテーマとして事業に取り組んでいますが,インフラ維持管理における課題も多種多様であると感じております.実際に現場で多い課題の例として,以下の2つを挙げたいと思います.
課題A インフラの増加あるいは老朽化により,障害発生リスクが高まっている
課題B インフラ維持管理に従事する若者が減少しているため,技能伝承ができない
例えば,交通インフラは高度成長期に作られたものが多く,老朽化が進行していることが問題視されています.2012年に発生した中央自動車道笹子トンネルの天井崩落事故では9人の死傷者が出ており,人命にも影響を与えています.
また,日本のインフラ維持管理は属人的な要素が色濃いため,日本人労働者の減少による維持管理の品質低下が不安視されています. 今後は,維持管理に必要なデータを蓄積し,維持管理を機械化・非属人化することが望まれます.
2. テキストデータを活用して、インフラ維持管理を高度化する
多種多様化するインフラ維持管理における課題を解決するためには,対象をモニタリングして障害発生を未然に防ぐ,あるいは業務改革により維持管理業務を機械化・非属人化する,などのインフラ維持管理の高度化が必要です.当社では,画像データ,センサーデータ,テキストデータ等を用いて維持管理の高度化に取り組んでいますが,本稿ではテキストデータの活用について説明したいと思います.
テキストデータの活用は,他のデータを活用する場合と比較して,以下の点で優れている場合が多いです( 図 2-1 ).
メリットⅰ モノだけではなく人の問題に取り組むことが可能である
メリットⅱ データが既に蓄積されているケースが多い
インフラ維持管理では,モノだけでなく,人・組織に問題が生じるケース(ヒューマンエラーなど)も多くあります.業務記録などのテキストデータは,人が記録したものが大多数であることから,人が抱えている問題が顕在化しやすいという特徴を持ちます.例えば業務記録に出現する単語の頻度を集計・可視化してみるだけでも,維持管理者が普段意識している内容が浮き彫りになり,新たな発見につながるケースがあります.さらに活用が進めば,これから実施する作業に類似した過去の業務記録を推薦するシステムを構築することで過去ナレッジを活用する,といったソリューションも考えられます.

また,インフラの維持管理に関する記録は,何らかの形式で文書として蓄積されているケースが多いです.
これは,維持管理業務の失敗が重大な障害につながる可能性がある場合は承認を要すること,業務担当者が複数いる場合は引き継ぎが必要であること,等が影響していると考えられます.データ活用に際して,そもそもデータがない,という問題を抱えている企業も多く存在していますが,テキストデータであれば企業内のサーバ等に蓄積されていることが多いです.
ここまでは,テキストデータ活用の利点を挙げましたが,活用に際して問題となることも勿論あります.直面することの多い,代表的な問題を2つ挙げたいと思います.
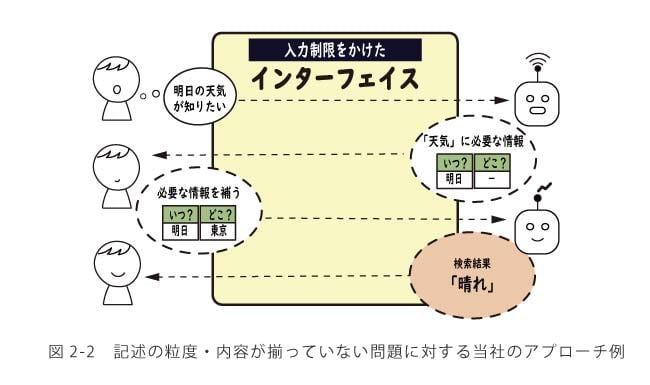
問題① 記述の粒度・内容が揃っていないケースが多い
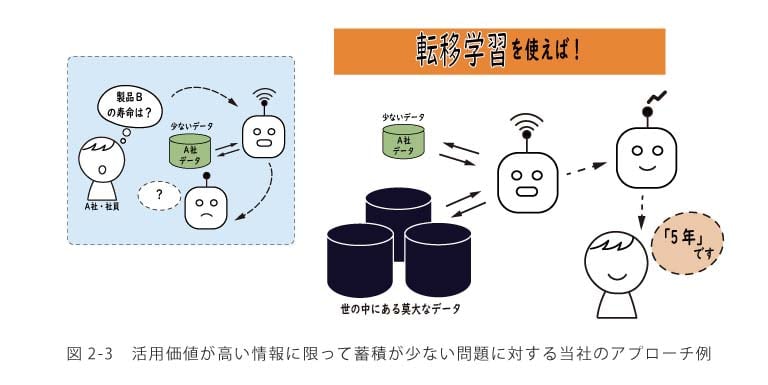
問題② 活用価値が高い情報の蓄積が少ない
維持管理業務の過程で蓄積されるテキストデータは,他者とのコミュニケーションが主目的となっており,データ活用を目的としていることは稀です.コミュニケーション目的では,早く記述すること,重要な箇所だけ記述することが重要視される傾向にあり,全体の蓄積として記述の粒度・内容が揃っていないデータになりがちです.
また,蓄積されている情報の質の偏りも問題となりやすい要素です.維持管理が成功しているデータと,維持管理が失敗したデータの両方が欲しくても,失敗データは蓄積量が極めて少ないというのが多くの企業の実状です.
3. テキストデータ活用における当社の取り組み
これまでテキストデータ活用の利点,代表的な問題について説明しましたので,上記の問題①,②を克服するための当社の取り組みについても説明したいと思います.
問題①に対する当社のアプローチは大きく2つあります.1つ目は,データ蓄積方法のコンサルティング,入力を規制するインターフェースの導入などに基づき,記述段階で粒度・内容を揃えることを目指すアプローチ,2つ目は,蓄積済みのデータをAI等で意味理解して,解析段階で粒度・内容を揃えるアプローチです.業務フローを変えずに進めることができるのは後者のアプローチですが,第三者が読んで価値のある情報が殆ど蓄積されていないようであれば,データ蓄積の方法から見直したほうが良いかもしれません.後者のアプローチをとる場合,専門用語に関する知識を維持管理業務の専門家がAIに教えるなど,フィードバックの要素を入れることが,良い仕組み作りにつながることが多いように感じています.
問題②に対するアプローチとしては,「転移学習」と呼ばれる手法を紹介しておきたいと思います.転移学習とは,ある領域で学習して手に入れた知見を,別の領域に転移させて流用する手法の総称です.今回の文脈に当てはめると,一般公開されている維持管理の失敗データを利用して,特定の企業で発生しそうな維持管理における失敗を予測する,といった用途が想定されます.
4. 最後に
本稿では,インフラ維持管理における課題,解決策,当社の取り組みについて,テキストデータ活用という視点から簡単に紹介させて頂きました.
私が最近特に関心のあるテーマは,3.の最後で述べた転移学習の適用です.失敗データは,一つの企業だけでは十分な量の蓄積ができない,データとしての公表が進みにくい,という特徴を持つことから,転移学習向きではないかと個人的に考えています.転移学習の適用に関しては研究中のため,内容まとまり次第,本レポートで報告したいと考えています.ご拝読頂き,ありがとうございました.
Contact
まずはお気軽にお問い合せフォームからお問い合わせください。